过去的一个月里,我花了一些时间解决隔壁部门遇到的网络负载均衡(LB)问题。为帮助我们进一步梳理在解决过程中遇到的问题,遂将其解决过程及带来的思考记录下来,以供后续参考学习。
摘要
本文内容主要是关于后台服务LB问题的定位、解决方案及思考过程的梳理与总结。
背景
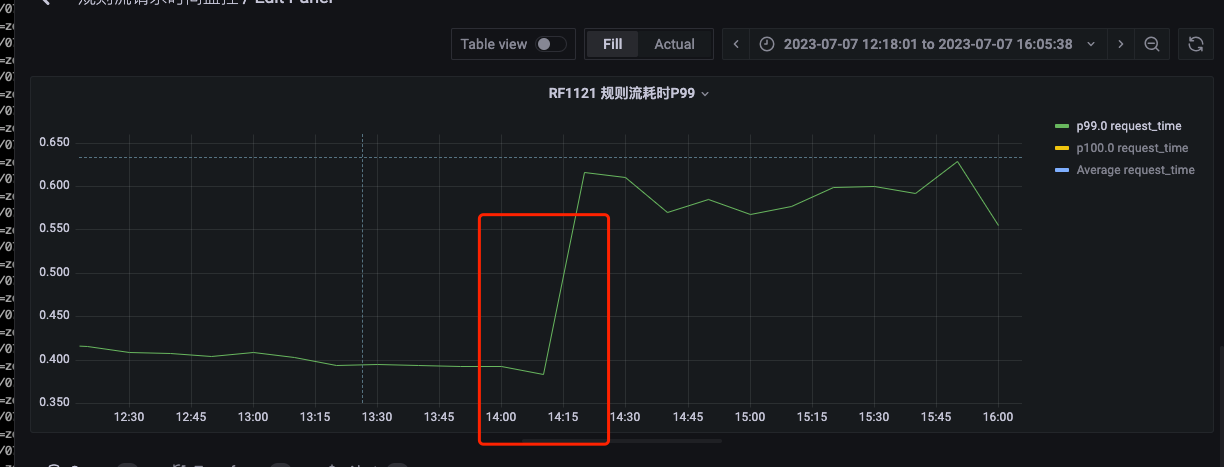
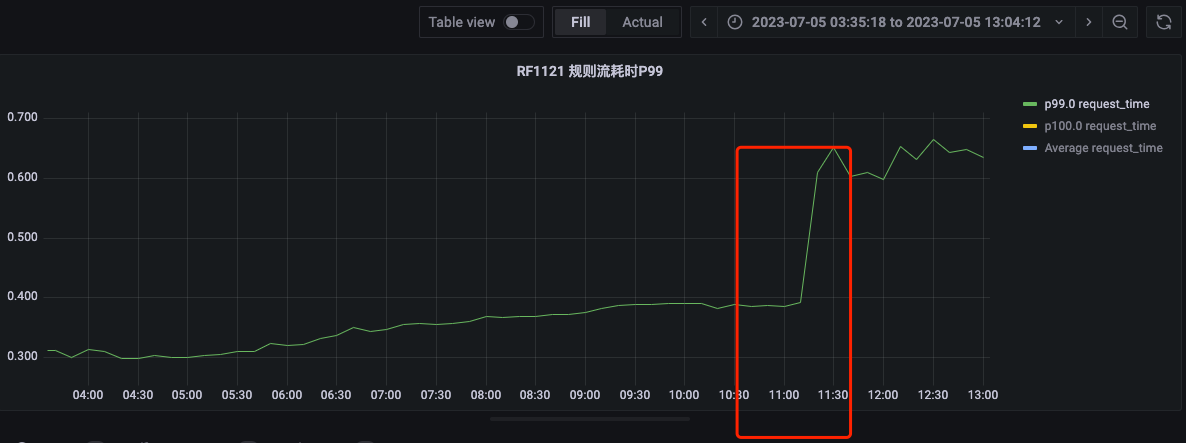
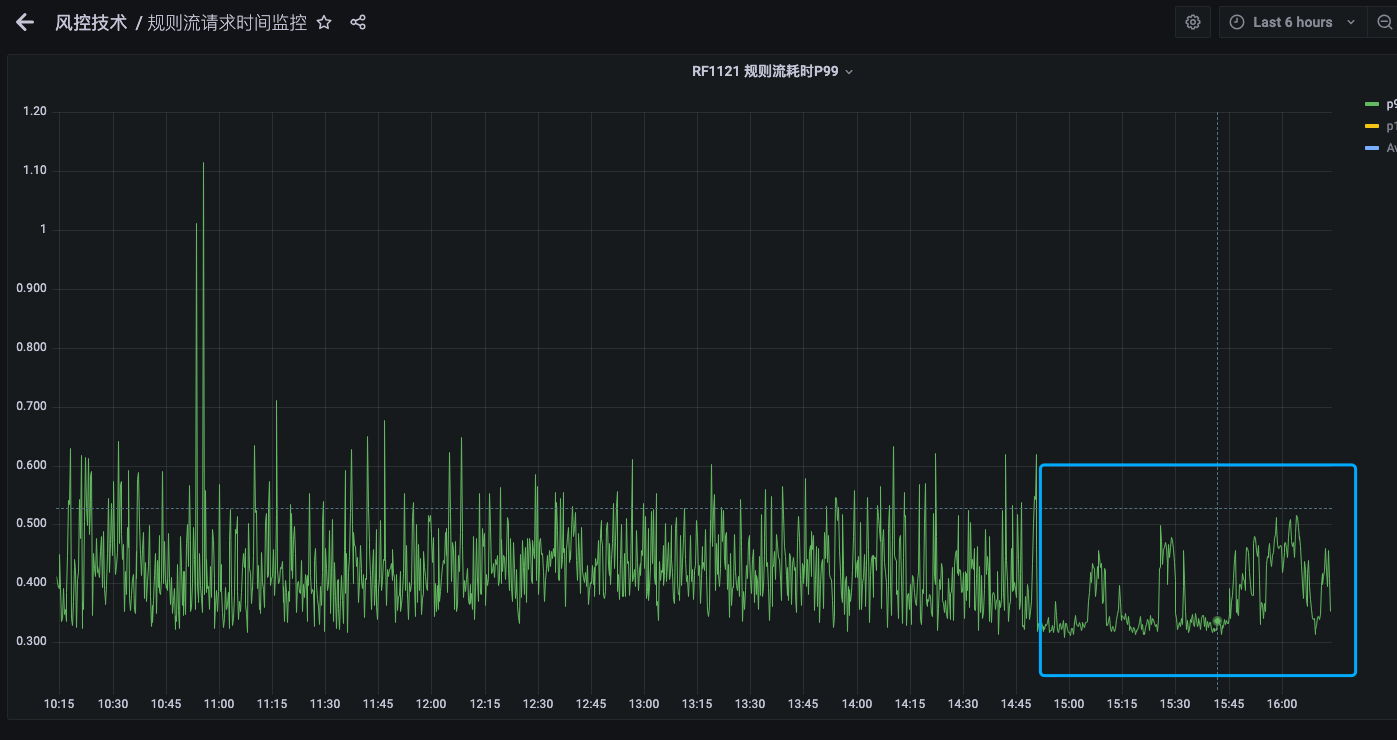
在6-29日风控规则引擎进行发版之后 定价规则流RF1121 (QPS 300-1000)的RT P99 发生明显改善,但是引擎的相关优化措施并未上线发布,该优化是在意料之外的优化,则需要查明发生性能改善的原因,为下一步优化工作做准备。
风控规则引擎规则流P99变化(6-29):
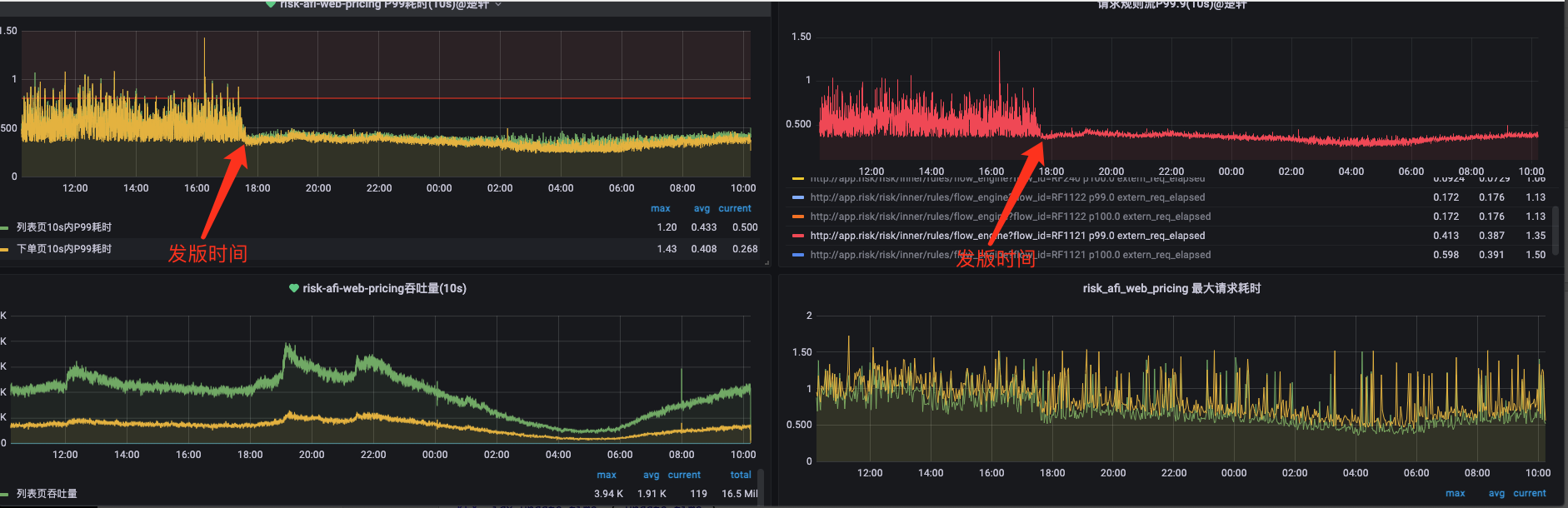
问题分析
对于发生性能改善的原因,我们将从以下几个主要的方面进行分析,抽丝剥茧得到最终答案,并为我们之后的性能优化提供可行方案。
引擎发版代码变更
因为性能优化时间与引擎的发版时间是保持一致的,我们最初的排查思路,是否引擎发版代码变更引起的性能优化。
引擎发版时间:
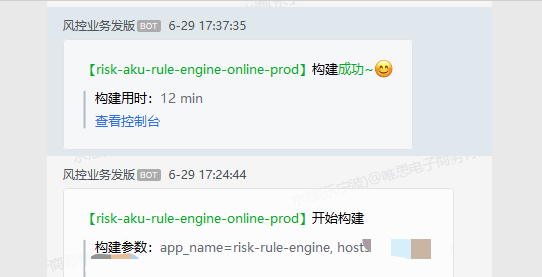
P99变化时间:
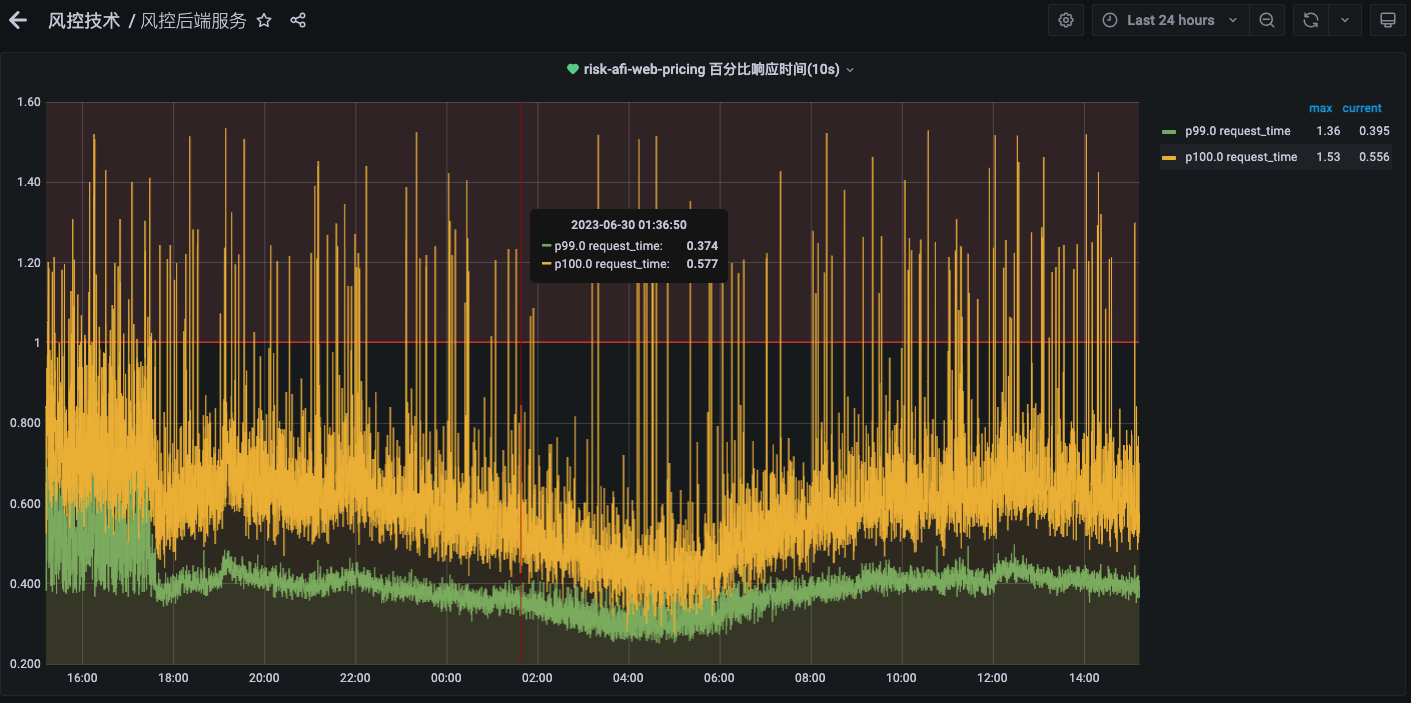
引擎发版代码变更:
代码变更内容分析
因为优化发生的时间与发版时间重合,且代码中涉及到可能会对服务性能优化的点包含以下几点:
Redis 请求由同步改异步
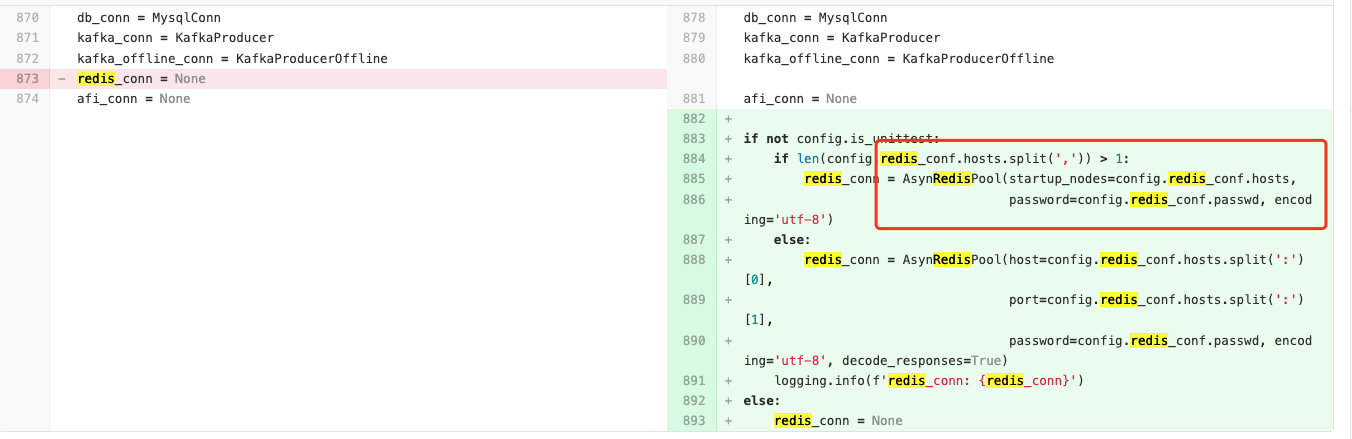
已经将redis 连接由同步更改为异步,但是根据代码逻辑在RF1121 中并不会调用到Redis,整体服务使用redis 较少。
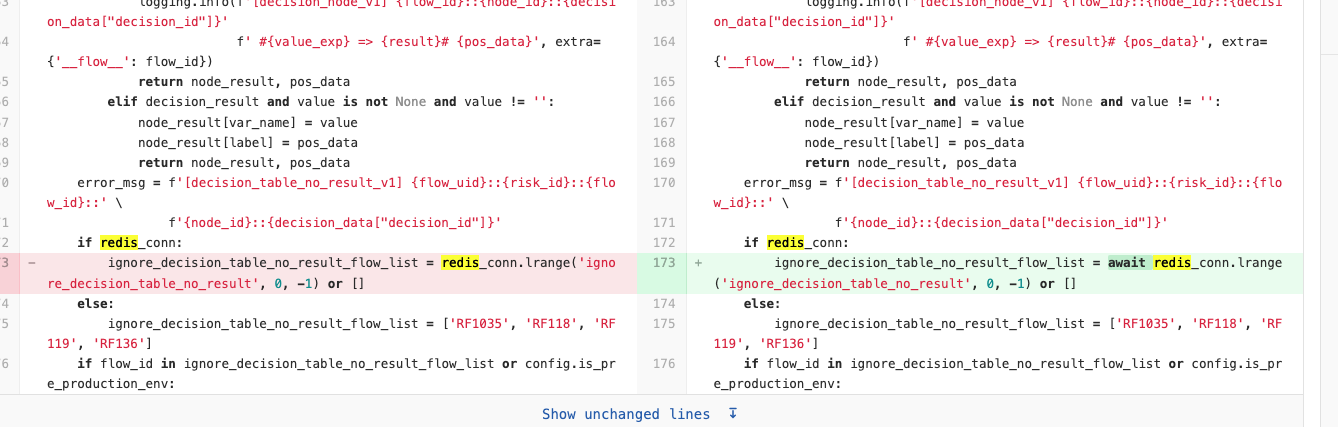
有可能会对性能造成影响的计算节点,使用到了redis,但是根据线上日志及代码逻辑判断,RF1121 并不会走到该处。对于同步redis 是否会影响服务整体性能,经过对服务器性能的验证,排除该种可能。整体响应p99 下降很多,而Redis 命令执行耗时一般在个位数ms,俩者不在一个数量级,则暂时排除该种可能。
进程内大数据读取方式改变
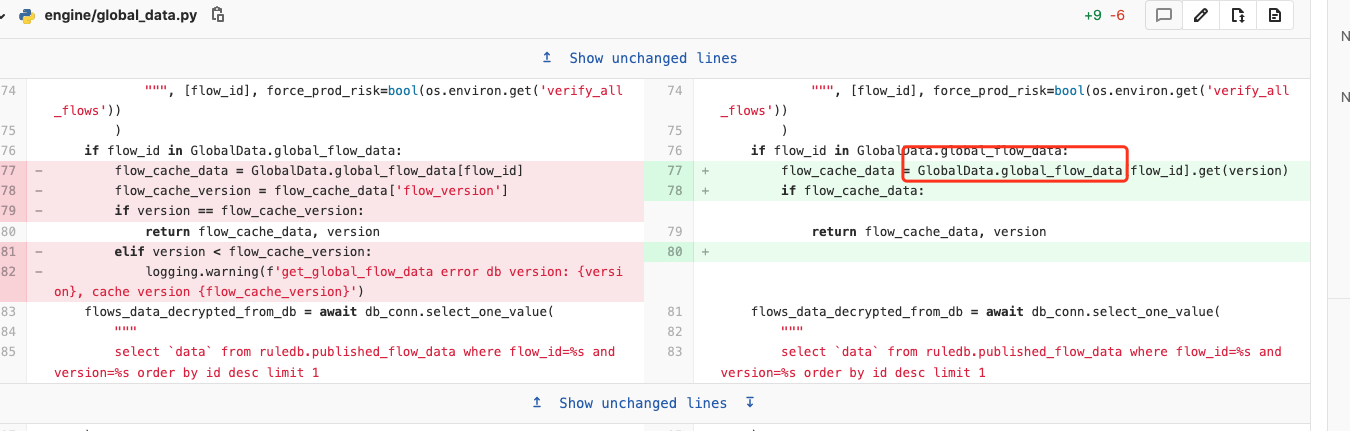
该 GlobalData.global_flow_data 为 50000 行左右的json格式数据,在改写方式后,少做一次操作,但是该类型在使用时均为引用类型,并不存在额外的内存分配之类的,在经过测试之后,发现更改前后性能差别很小,则暂时排除该种可能。
在节点执行结束时增加await操作
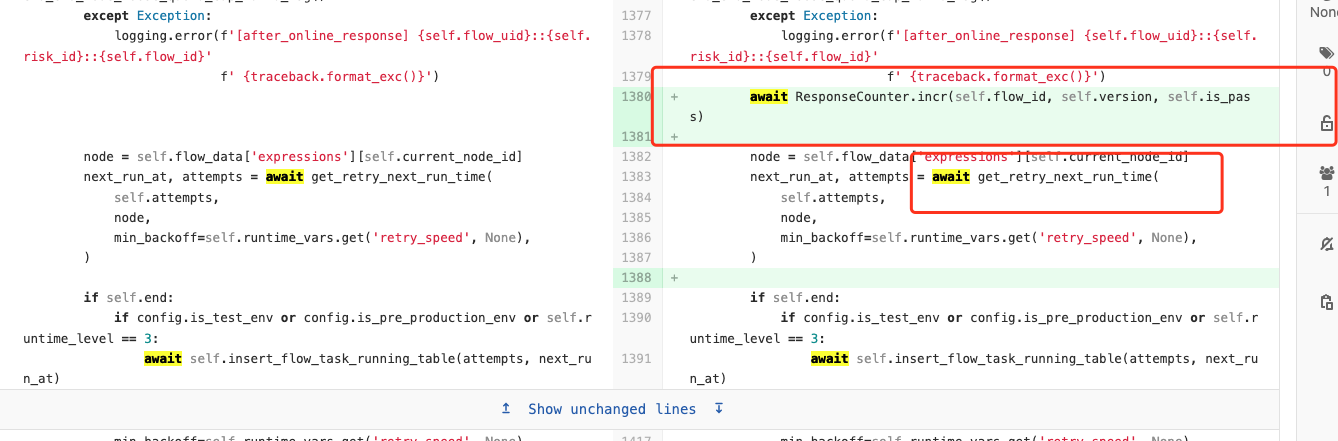
原来的逻辑中也会在节点结束后进行await get_retry_next_run_time,但是该方法是并无真正的异步操作,实际为同步方法。
阿里云机器性能波动
由于之后在未发版的情况下,服务P99 性能出现明显下降,开始怀疑到阿里云提供的服务器性能发生了波动,遂开始定位服务器性能。
阿里云机器性能变化
磁盘IO变化图:
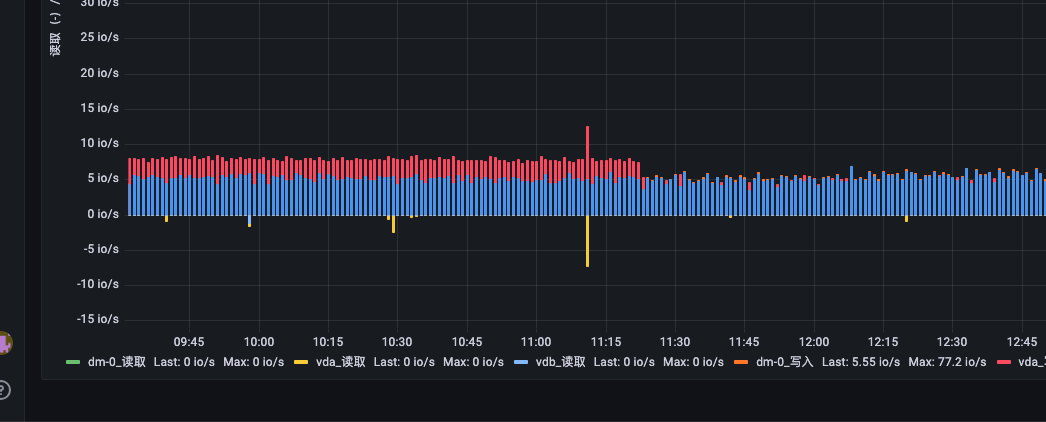
阿里云机器监控指标:
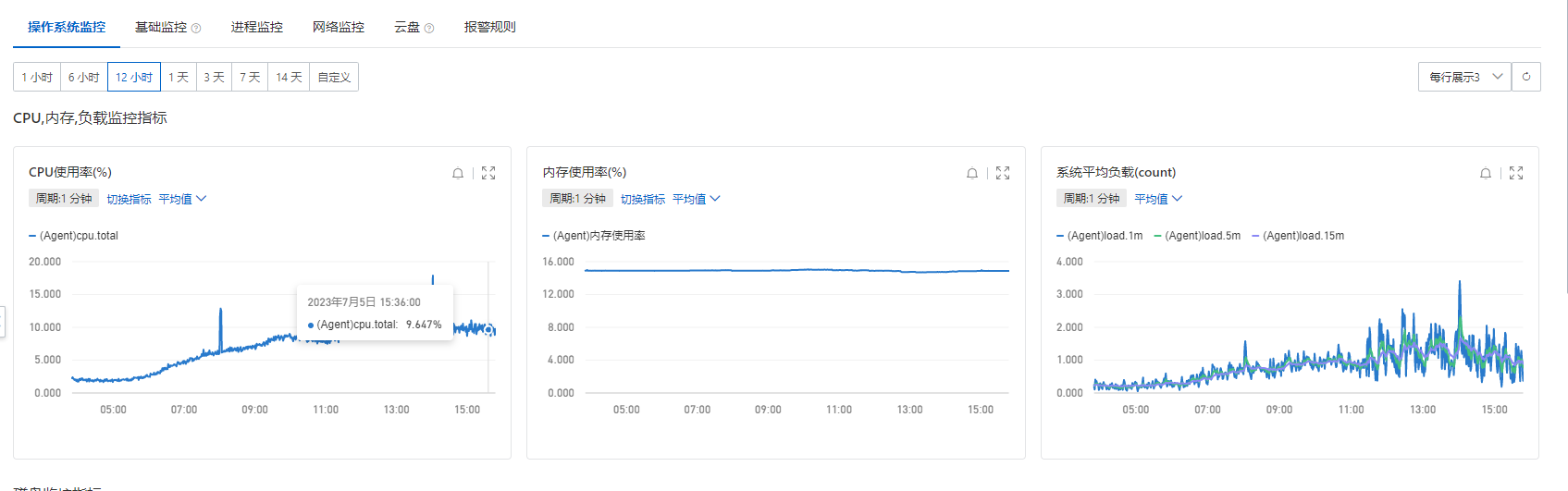
阿里云机器TCP指标变化:
该处对于机器性能指标的变化,很难确定是P99波动引起的原因或者现象,从机器监控上看,运维对比其他部门的服务器IO监控,属于正常范围。vda 如上图显示写入变慢一倍,但是vda 是系统盘,服务部署在vdb,与服务无关,且IO峰值在2000,现在仅达到7-8,影响很小。通过下线流量验证服务器性能,并找阿里云方面确认之后,应该不是服务的原因,暂时排除掉该原因。
外部Redis PloarDB等组件性能波动
Redis性能波动
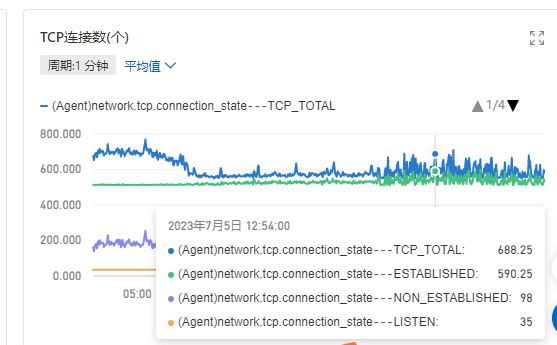
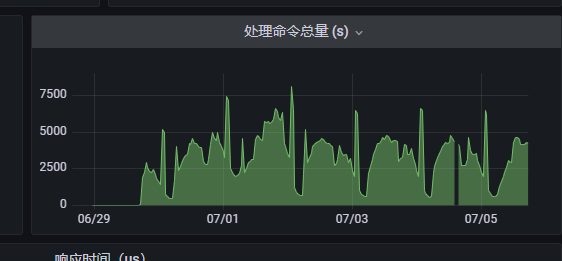
redis 处理命令总量(断层为前端显示问题):
redis 流量:
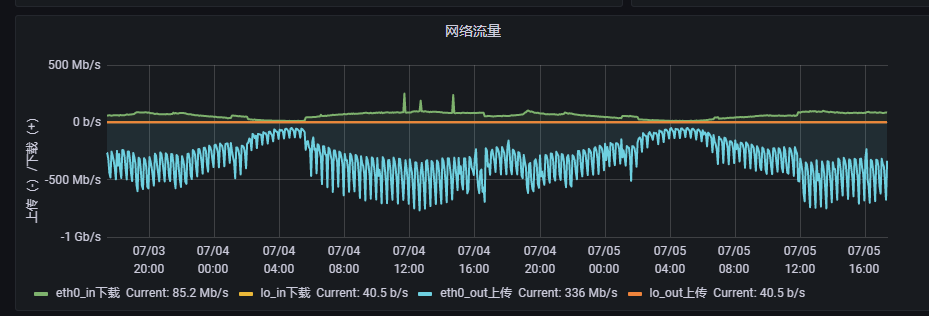
引擎服务为独立部署redis,从监控上来看的话,并无问题,遂暂时排除Redis问题。
PloarDB 性能波动
PloarDB 每秒查询数量:
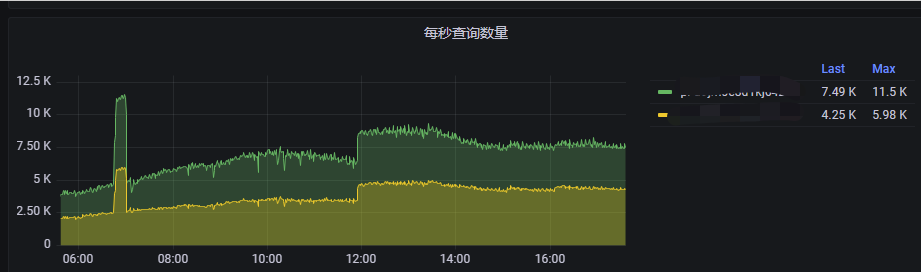
PloarDB 查询量方面确实存在波动,但该量远未达到其极限,且查询量峰值和P99波动不一致,且无slow sql,遂暂时排除该原因。
请求流量分布不均匀
引擎服务流量分发现状:服务部署在m台服务器上,每台服务器上启动n个进程,在nginx侧将流量采用轮询策略分发到m*n个端口上,基于后端服务器端口做的流量分发。
请求分布情况分析
在发生P99波动前后的时间段,观察固定时间范围内机器上的请求分布情况。
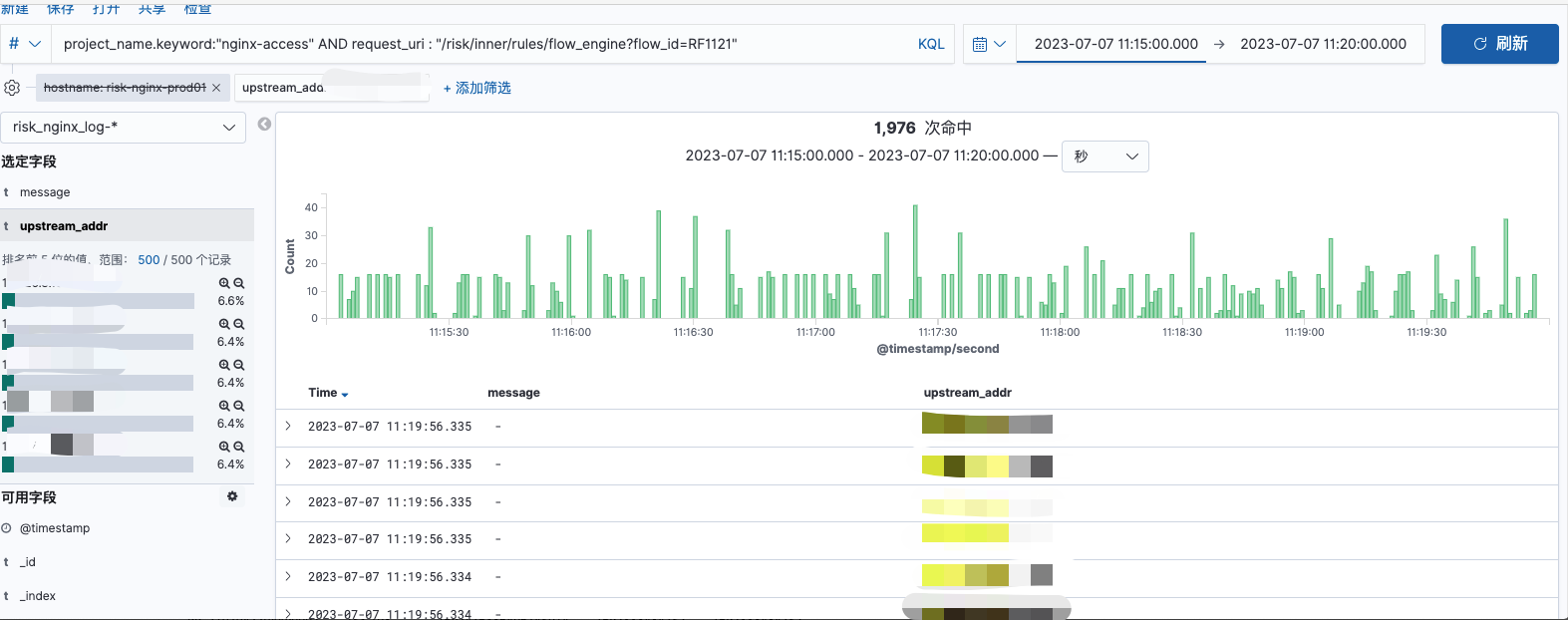
单机器P99 性能较差时请求分布:
单机器P99 性能较好时请求分布:
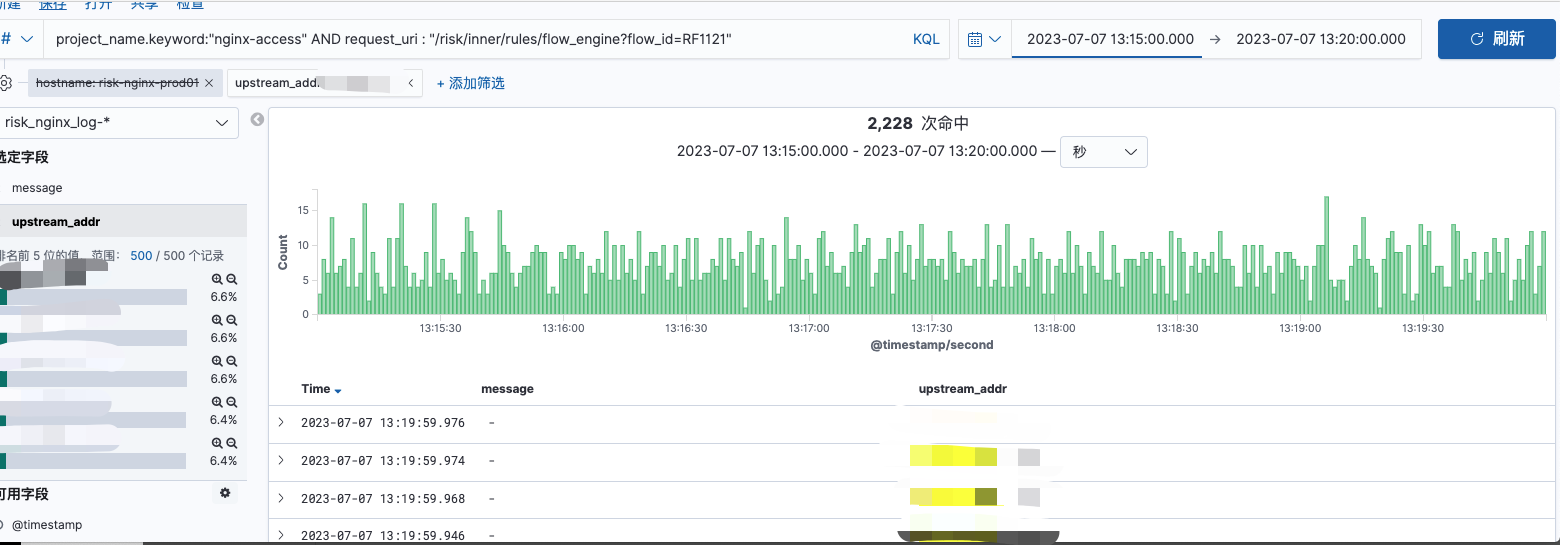
如上俩图,均为同一台机器,时间范围均为5mins,请求量存在较少的差距,但是请求量的分布在第一个图中峰值可达到40,且存在较多请求间隙;在第二个图中,请求较为稠密,且请求量峰值仅为第一图中的1/3。则在性能较差时,请求量到单台机器上的分布是不均匀的,但是对单台机器的流量分发总量是无问题的。
因此需要明确是否nginx流量分发存在问题,由在 引擎服务流量分发现状 中已经指出,引擎nginx的流量分发是对端口负责的,与机器无关。
单端口P99性能较差时的请求分布:
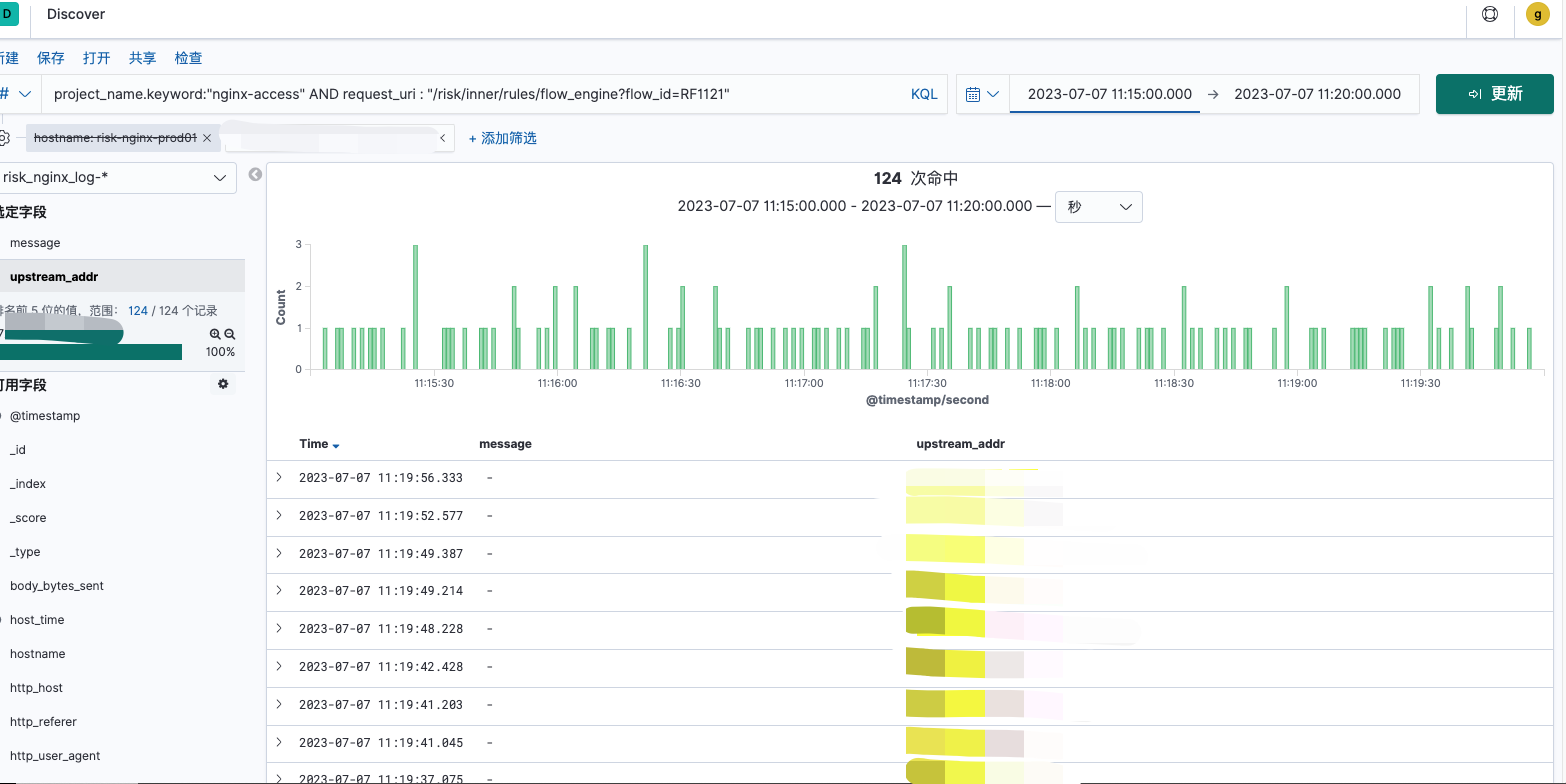
单端口P99性能较好时的请求分布:
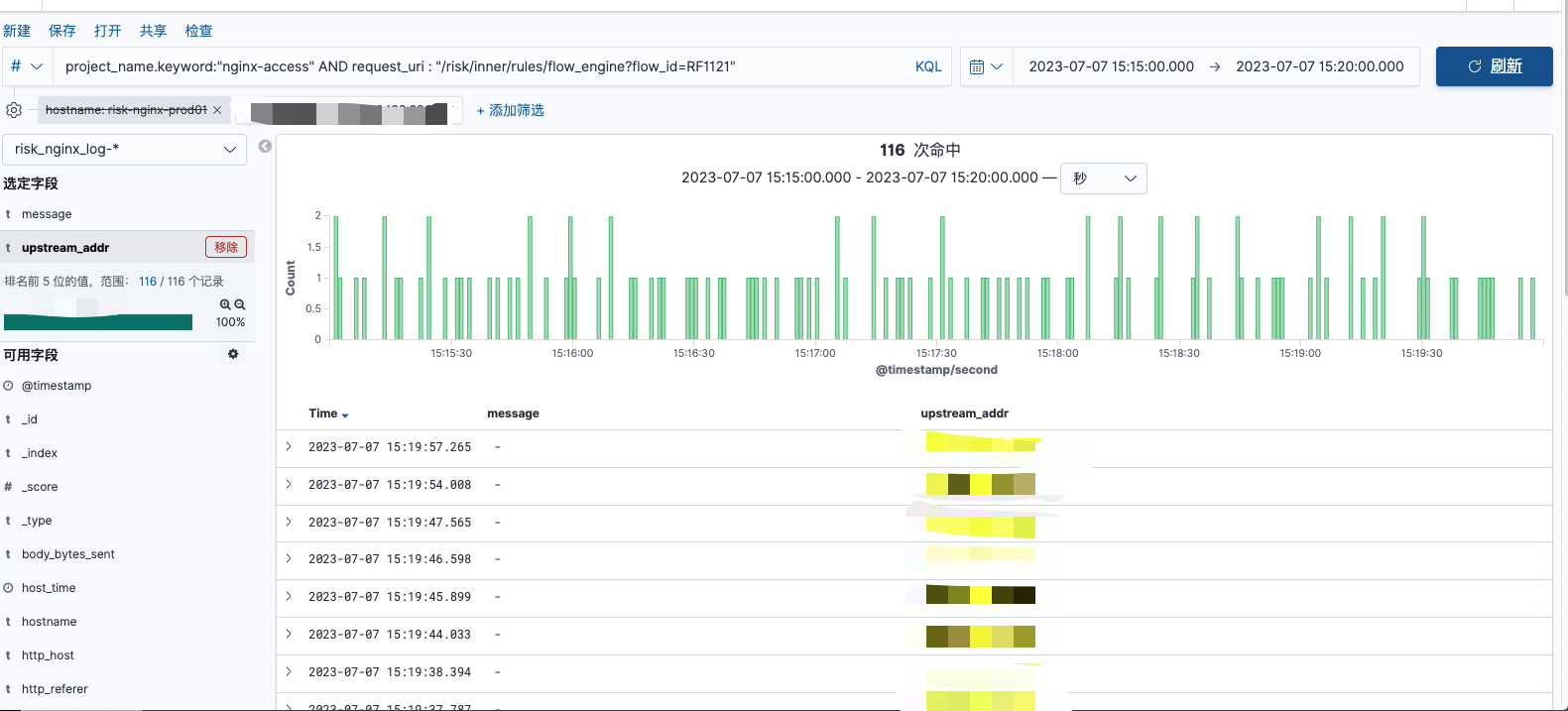
由上图可看出,nginx 在对流量分发时是无问题的,无论P99 性能好坏时,nginx对某个端口的流量分发总是均匀的,nginx分发是无问题的。
LB到nginx 流量
由于我们的nginx 并非单台nginx,且在nginx之前的LB,采用的是4层LB,则天然对于某个url的请求量,从LB到四台nginx上分发的是会出现不均匀情况的。
4台nginx 整体流量波动:
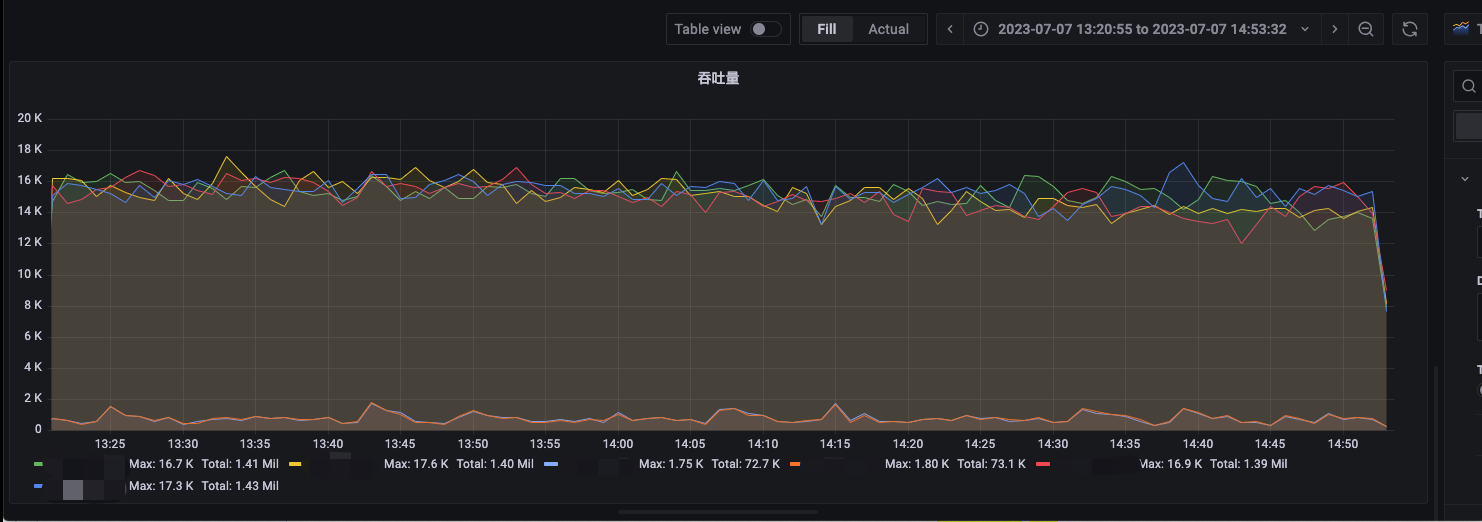
4台nginx 上某个url 请求量波动:
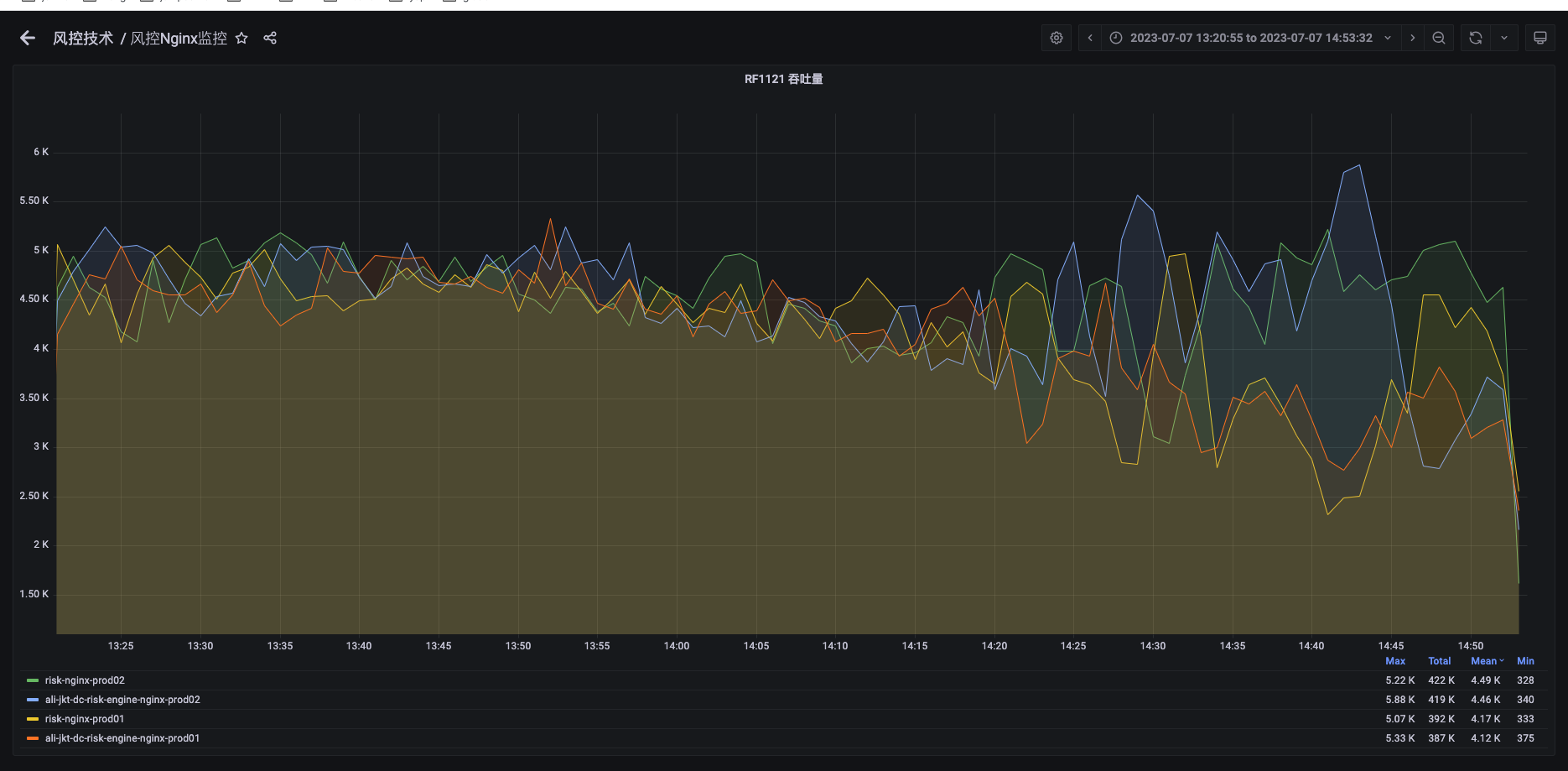
不同nginx 间单url请求量差异波动:
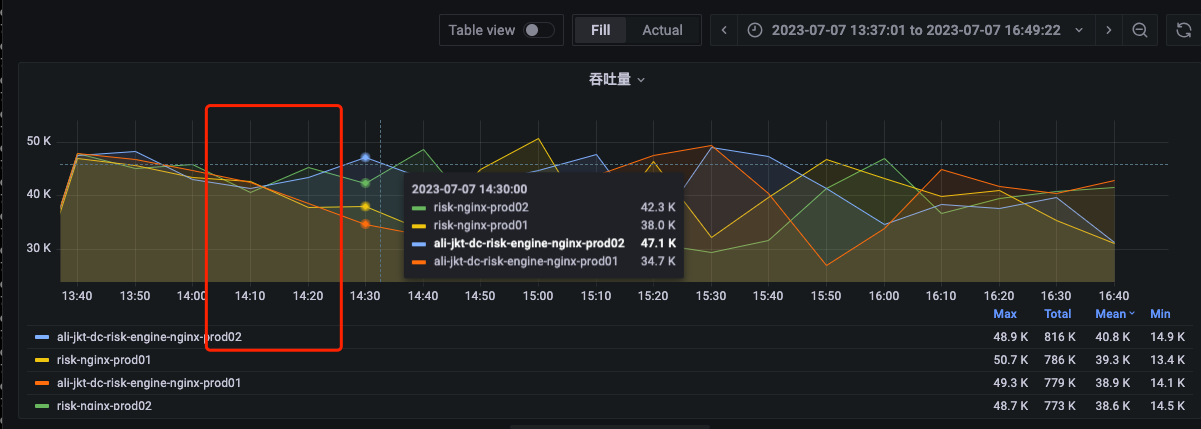
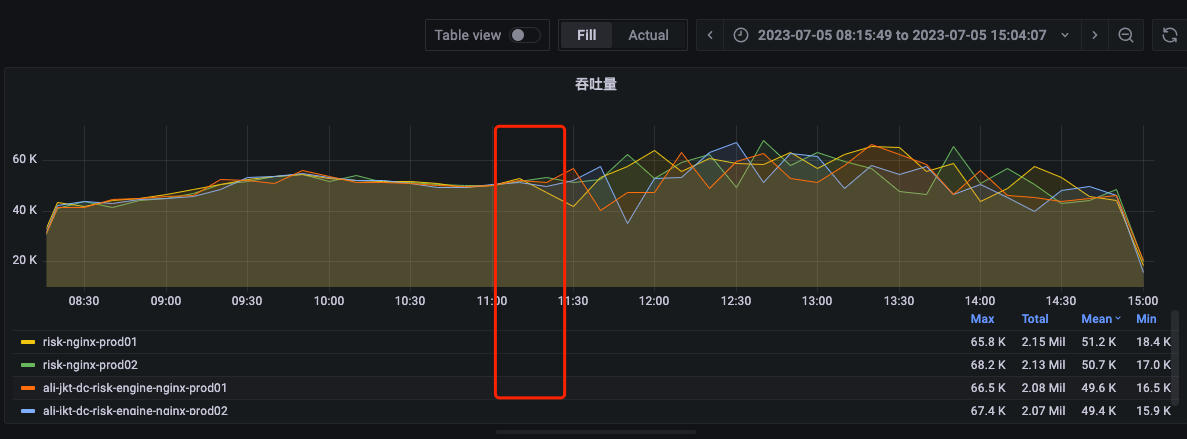
服务P99变化:
由上俩图可发现,当nginx RF1121 流量发生波动时,对应的RF1121的P99耗时则增高。该处的原因,假设一开始各nginx到服务器的流量分发均匀,但是当某台nginx的流量产生波动时,不同nginx分发RF1121的请求量会发生变化,导致不同nginx的分发速率不一致,会导致一些请求的分发会出发重合,导致请求分布不均匀,但是单台nginx到单台机器的单个端口仍可保持均匀。
nginx到后端服务流量
由于上述原因使用4层LB,且是多台nginx的情况下,针对某个url的请求自然是不会均衡的,但是在我们的nginx配置中对后端流量的分发中,也存在着一些问题。在我们nginx配置文件中的写法之前是:
ipA:port1 ipA:port2 ipB:port1 ipB:port2 ipC:port1 ipC:port2 eg:当并发为2的请求到达当前nginx时,会使俩个请求都到了ipA,并不会均匀的分发到不同机器,在nginx层面做的是对端口的均匀分发,但是在同一台机器的不同端口,服务器资源是共享的。该配置文件的写法存在请求分配后端服务机器流量不均的情况。
解决方案
由上述问题分析,我们已经初步得到一些答案,现在我们将开始逐步验证这些猜想,并且需采用对线上服务影响最小的方式开始进行灰度验证。
nginx到后端服务流量分配
由在 nginx到后端服务流量 中提及到的问题,则在不改变nginx负载方式的情况下,改写nginx配置,采用如下这种方式可以使并发请求到nginx后,nginx分发到各个机器时更加均匀:
ipA:port1 ipB:port1 ipC:port1 ipA:port2 ipB:port2 ipC:port2 在某次服务发版前后的单nginx到单后端机器请求分布情况:
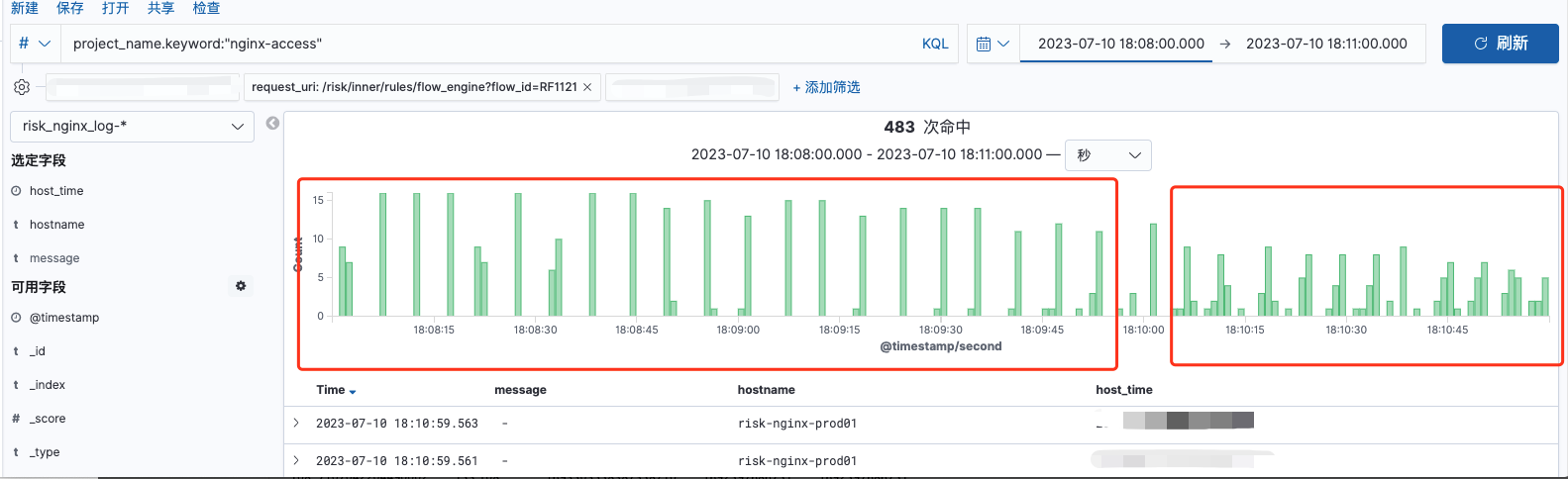
由上图可见,在某次发版之后,流量较为均匀,无大的波动,则会保持均匀较长的时间,P99 最差时 峰值为15,较好时为7-8,但仍存在规律性的峰值,是不正常的表现。则更改nginx配置并重启,开始验证我们关于nginx到后端服务的流量分发猜想:
更改nginx配置之后的单nginx到单后端机器分布情况:
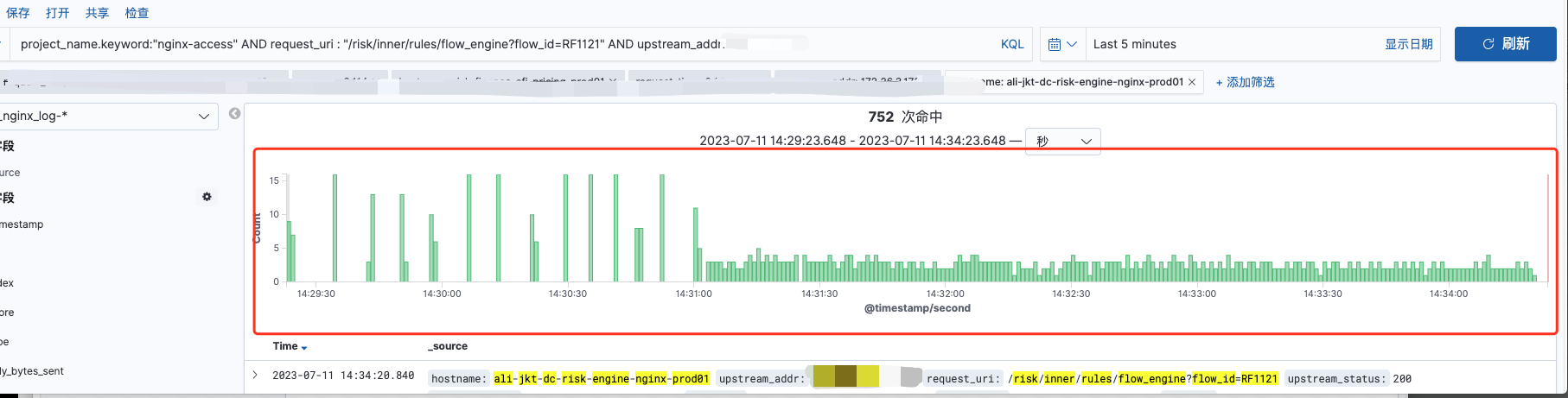
如上图,不存在7-8的规律峰值,最大峰值仅为2-3左右,请求分布更加均匀。
服务P99 耗时:
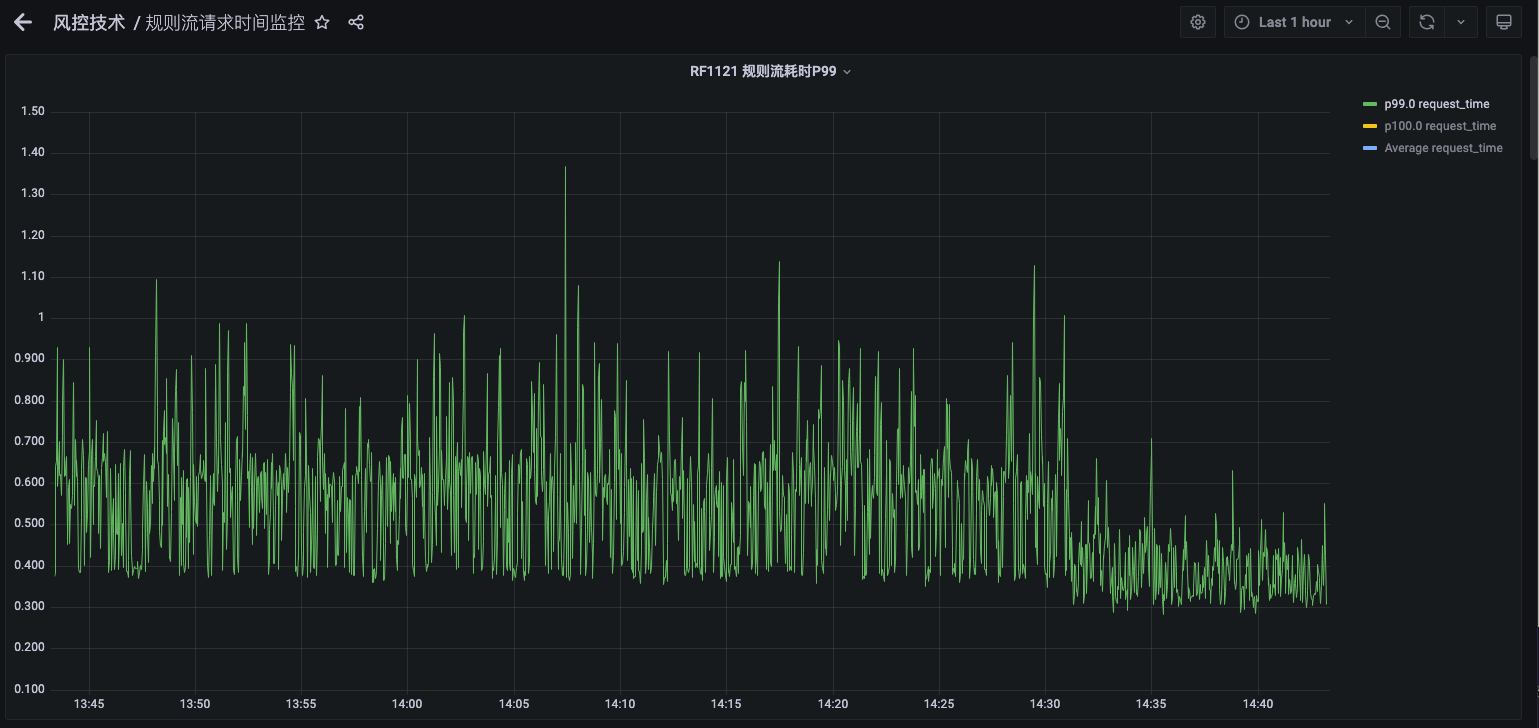
服务P99 耗时出现明显下降(1/3),但仍存在明显的P99毛刺,只是相对之前没那么明显,则下一步从LB到nginx流量分配做改进。
LB到nginx流量分配
由上述更改nginx配置前后的性能差异,已经验证是我们对于nginx到后端服务流量分发的影响,由此,我们开始验证LB的问题。将四层LB更改为7层LB,并观察流量波动。
更改LB后不同nginx某url请求量:
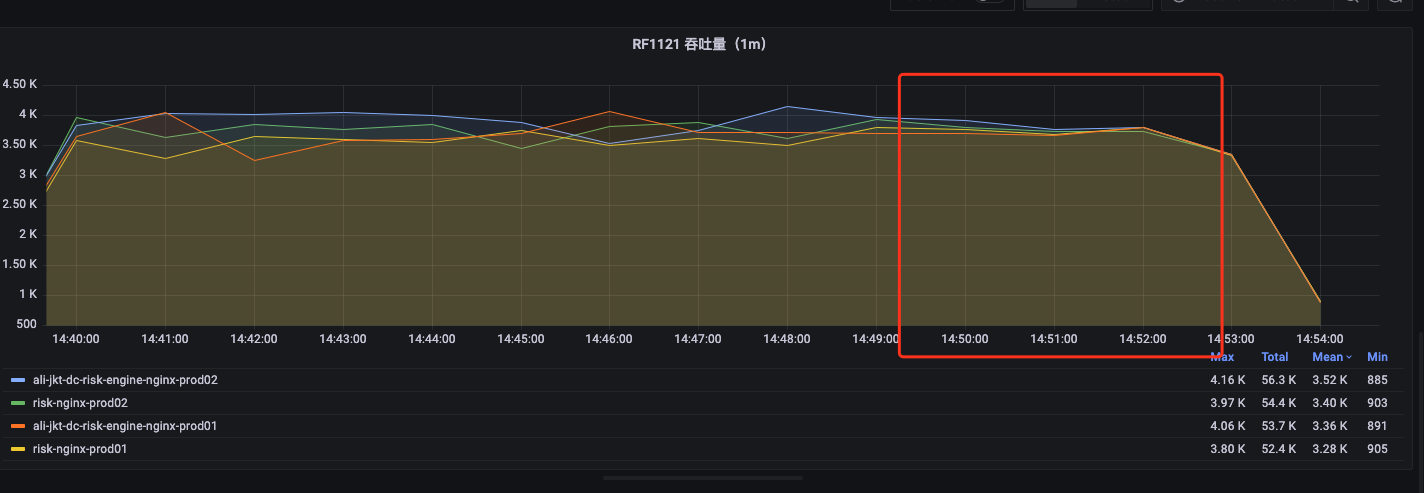
服务P99响应:
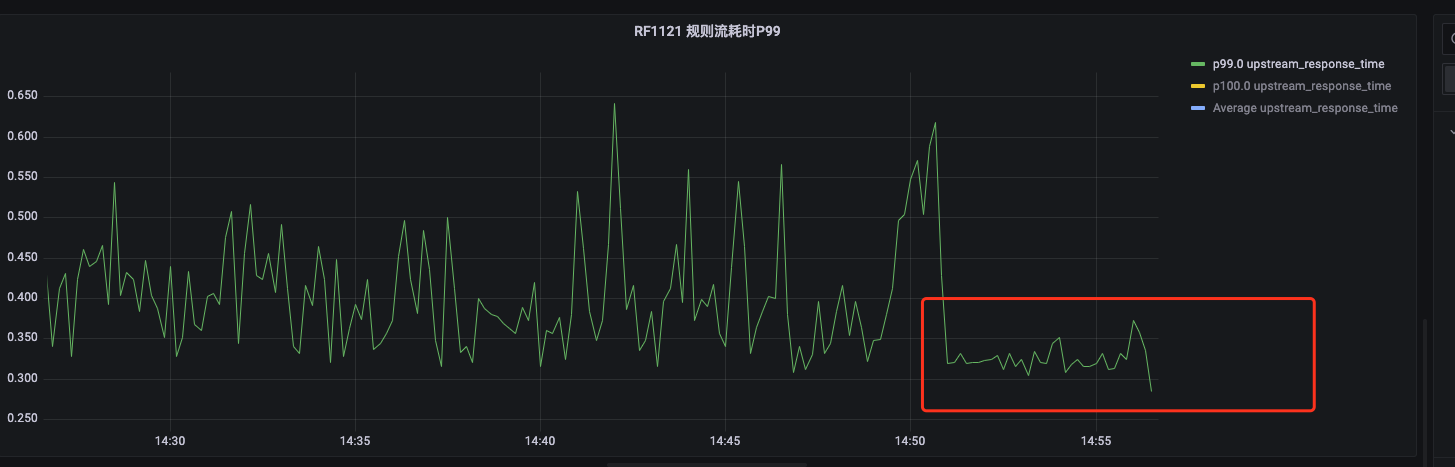
如上图可知,在我们更改LB后,服务P99性能存在明显的改善,但是仍存在部分p99的毛刺,这些部分应该是由于虽然我们流量均衡分发,但是我们采用多台nginx的情况下,仍然会存在部分端口的流量不均衡。
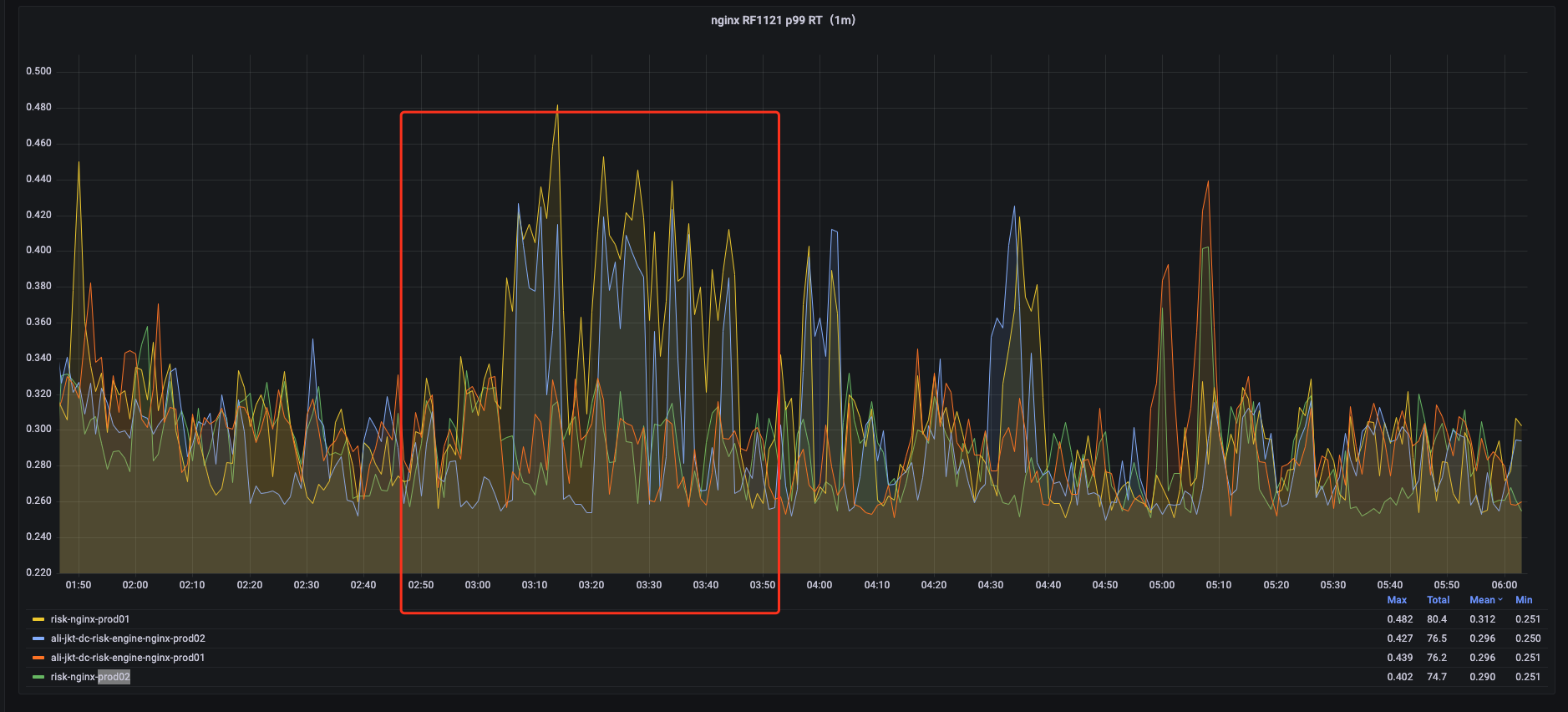
更改LB后服务P99毛刺:
则对于这种情况,因为多台nginx之间是不连通的,之间是没有配合的,所以会出现这些问题,则接下来,我们将从切换单台nginx解决该问题。
切换单台nginx
对于在 LB到nginx流量分配 中遗留的问题,我们对线上发生这些毛刺时的服务,做了一些观察。
服务P99发生毛刺不同nginx机器p99:
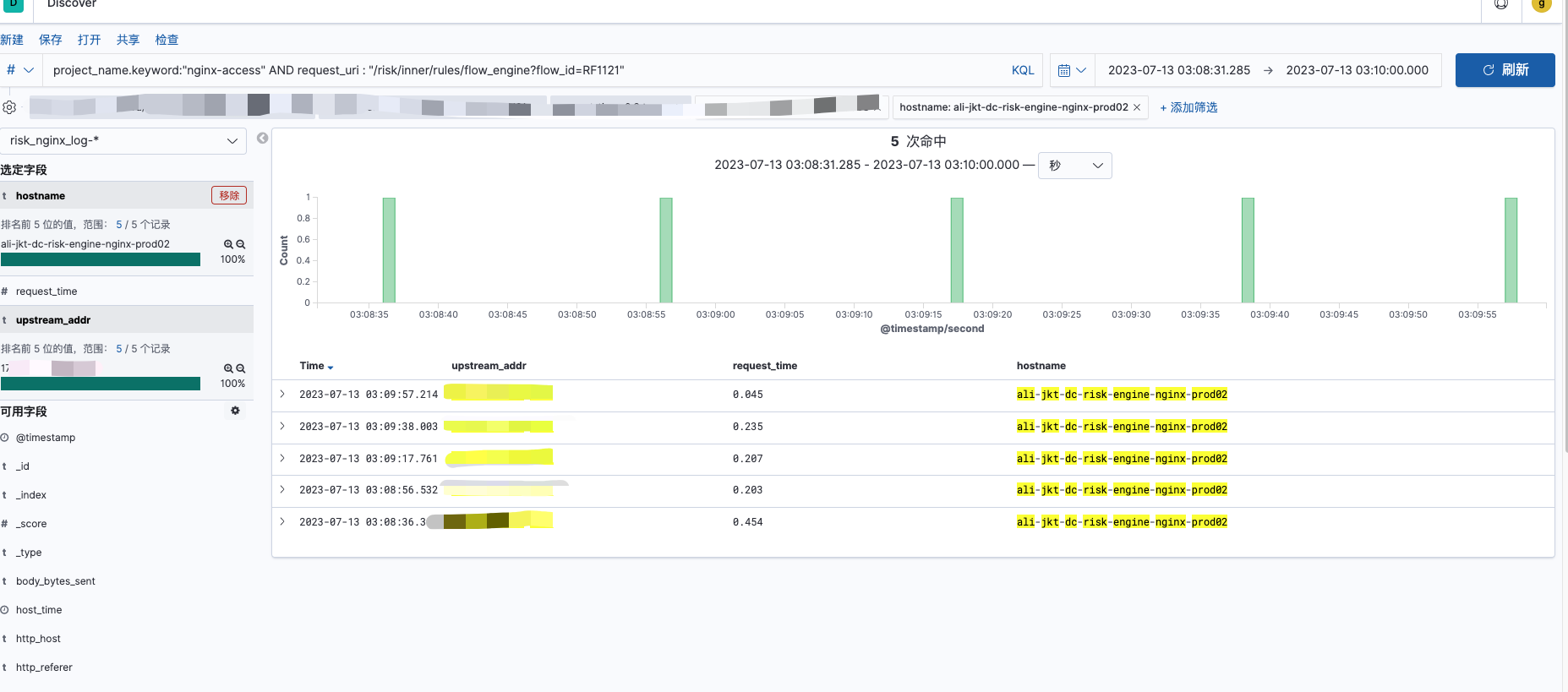
单台nginx到单个端口的请求分布:
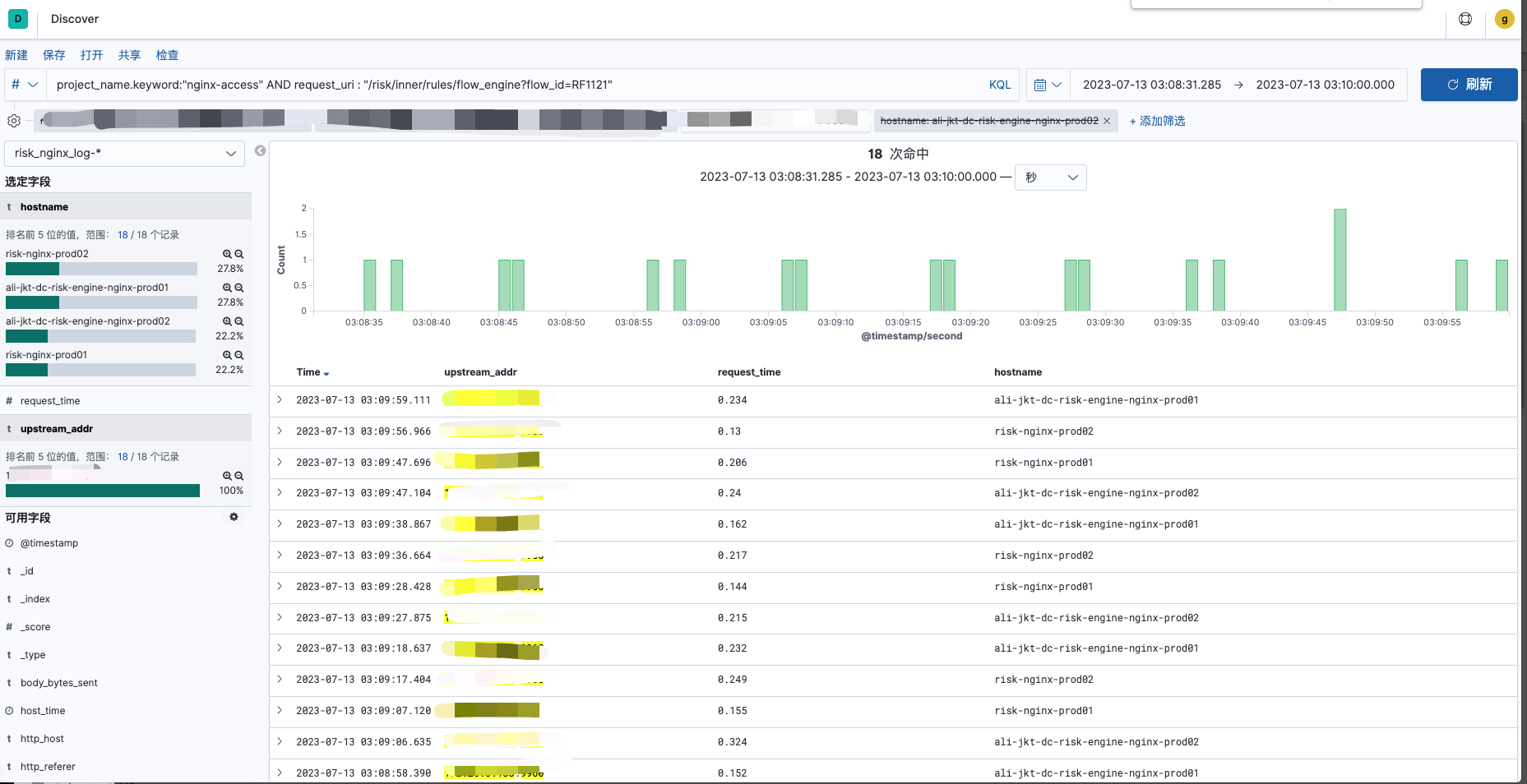
多台nginx到单个端口的请求分布:
耗时的端口:
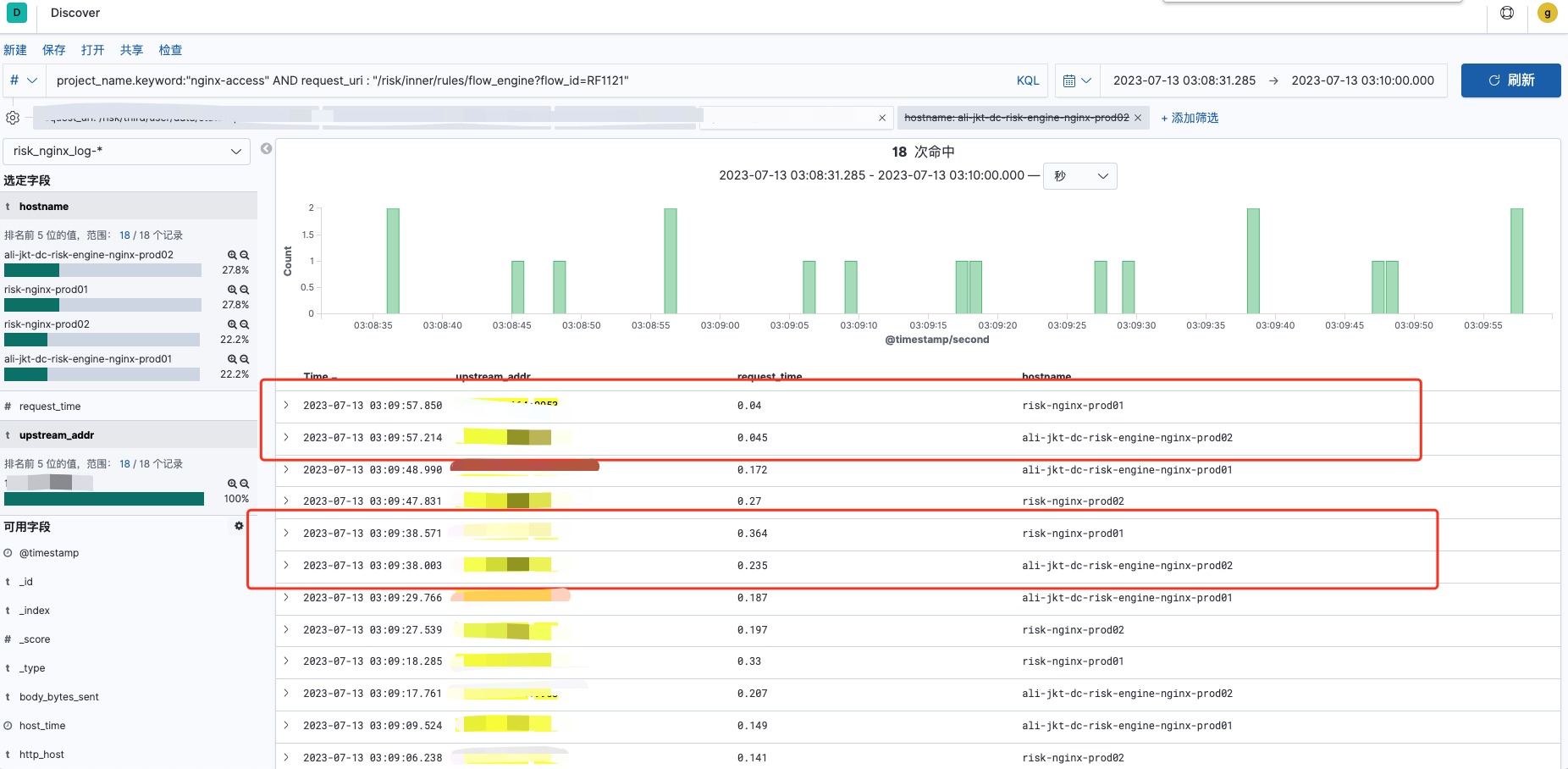
由上述图可知,在服务p99发生波动时,一定是俩台或者俩台以上的nginx P99出现波动,不存在单台nginx P99出现波动的情况。则出现P99 波动时,是俩台或者多台nginx的请求发生了部分重叠,导致有些端口的请求QPS达到4,会出现耗时高的情况,则开始下线nginx的操作。
则采用逐步下线的方式,先升级nginx机器配置,再下线俩台,则理论上单端口QPS最大为2,有效减少抖动:
下线俩台nginx后服务P99:
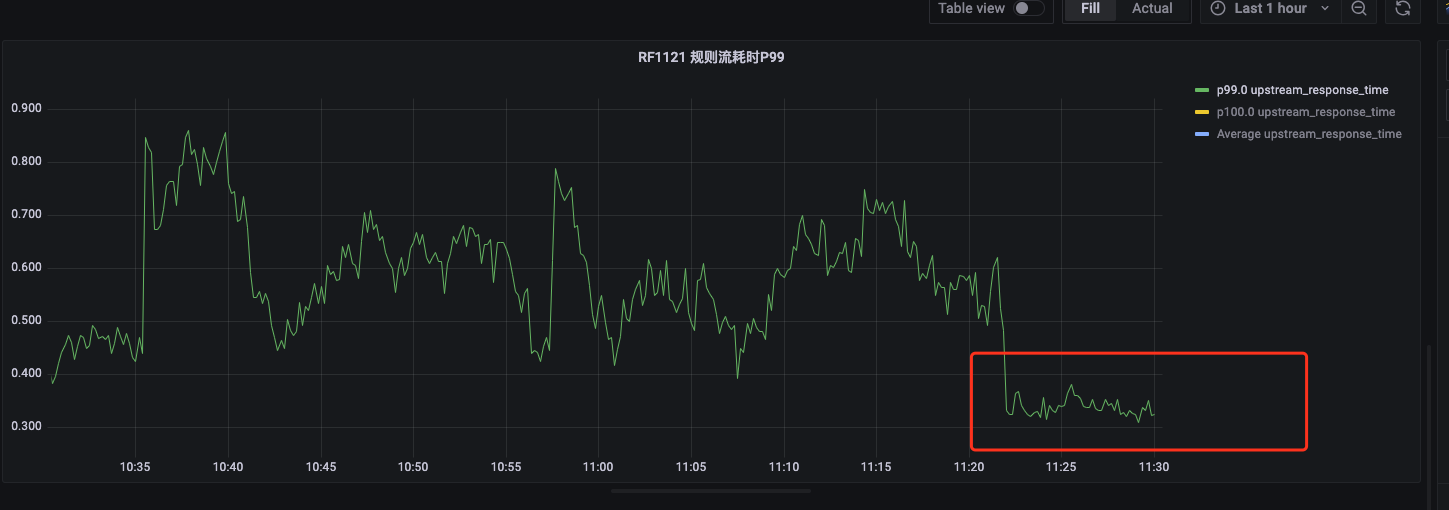
在下线俩台nginx后服务p99 明显改善,在此基础上继续下线nginx服务器数量,将nginx服务器数量减少为1:
线上1台nginx时服务P99:
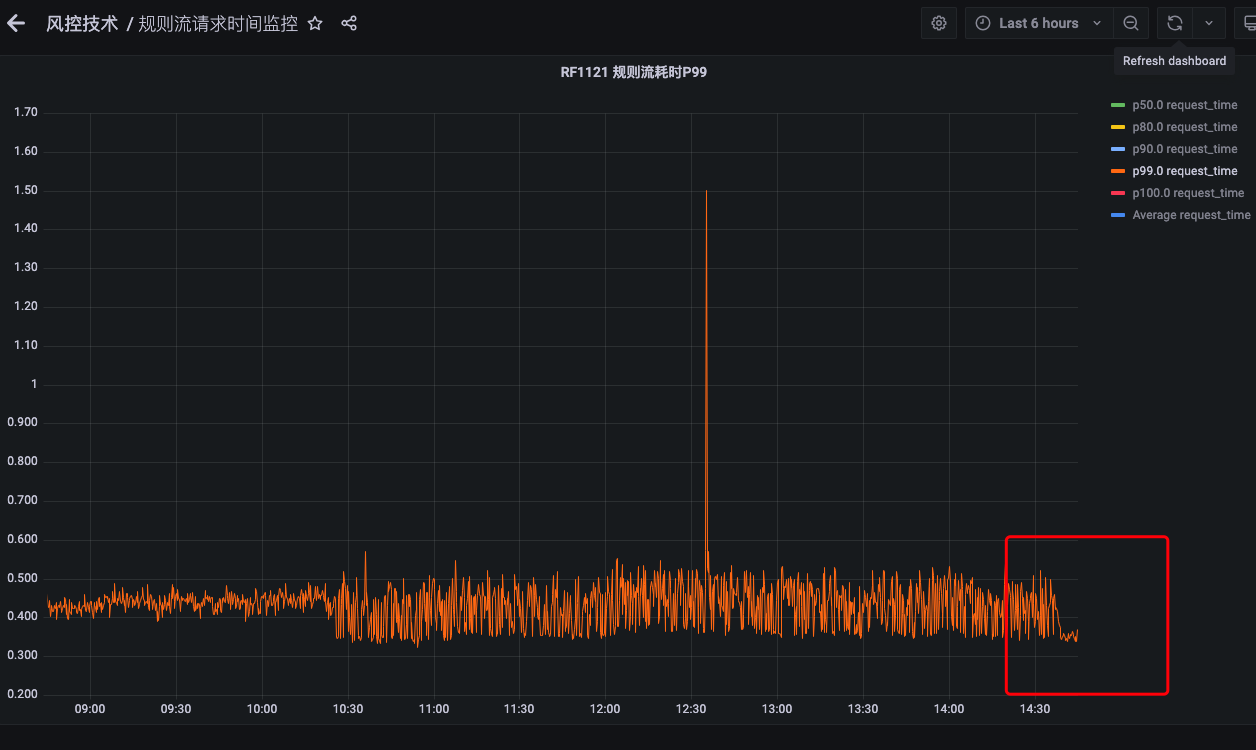
如上图,服务P99得到了进一步的改善,且平稳运行,则在最后,使用单台nginx(主备)的情况下,无需再使用7层LB,将LB切换为4层,开始逐步下线冗余后端机器,最终在下线一半机器的情况下,服务P99仅为未优化前的1/3
总结
本次优化是从流量负载均衡的角度,由LB到NGINX再到单台服务器,实现基础架构层面全链路的负载均衡优化。主要从LB、nginx upstream 分发、 多 nginx 配合等方面,并结合风控引擎服务的特殊性做出的一系列优化,取得了比较明显的效果。
优化后服务P99(稳定在350ms 左右):
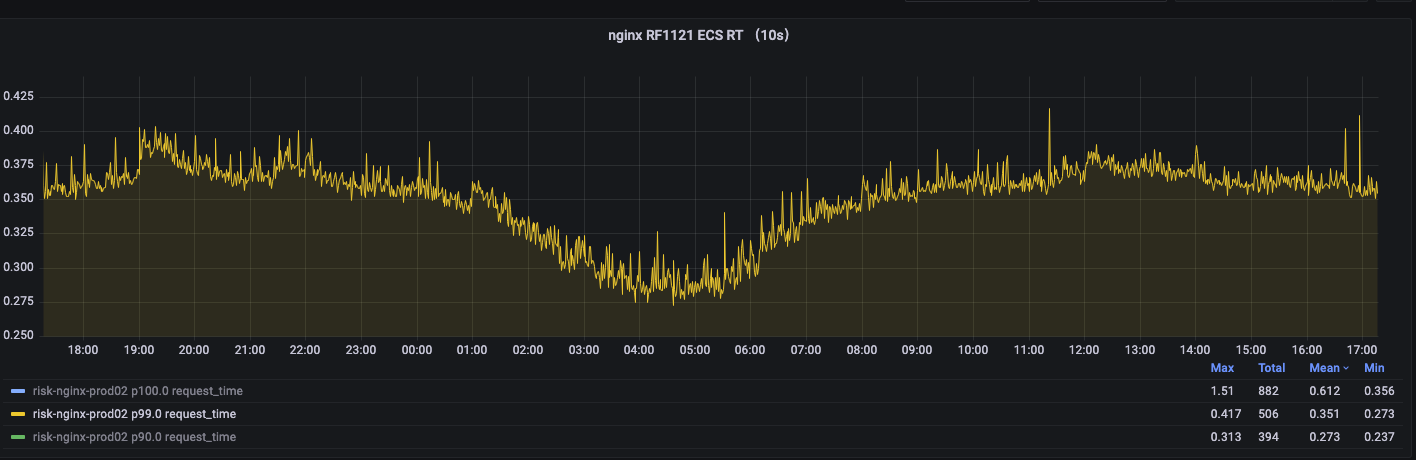
未来规划
APISIX 网关替代 NGINX
采用apisix集群模式,可完全避免多台nginx间无法合作的问题,且对流量的负载均衡策略,可以更加定制化,符合我们的服务;目前部门内部已存在部分接入apisix的服务接口,有一定的技术基础,且公司其他部分已有部分完全切换apisix。
在线服务接入APM
当线上出现性能问题时,在线服务接入APM,可以更快速且准确地定位到性能瓶颈所在,避免现在这种低效的排查问题方式;目前已经在预研阶段。
后端服务器接入守护进程
在每个服务器前做负载均衡,则可从工程层面解决掉服务器内部进程负载的问题,使多核服务器中的不同进程调度更加均衡,提高服务运行效率;目前已经在微服务改造调研阶段。
参考文章
https://docs.nginx.com/nginx/admin-guide/load-balancer/http-load-balancer/
http://nginx.org/en/docs/http/ngx_http_upstream_module.html
http://static-aliyun-doc.oss-cn-hangzhou.aliyuncs.com/download/pdf/DNSLB11825295_zh-CN_cn_181214111834_public_df469752bf687c1ff97c4331eba6090f.pdf
https://iq.opengenus.org/layer-4-layer-7-load-balancing/
https://blog.envoyproxy.io/introduction-to-modern-network-load-balancing-and-proxying-a57f6ff80236