之前在阅读别人的代码时,发现了一个有趣的现象,那就是在多核环境下,对于一个64字节的结构体,如果其成员变量不是64字节对齐的,那么在多核环境下,对其进行读写操作时,会出现性能下降的情况。这篇文章就来探究一下。
多核环境下cache line 测试
前段时间在阅读 uber/rat_limit 代码时注意到其在定义struct时,会填入补充字段补至 64 byte来避免 cache line 的 false sharing,于是决定花些时间来探究一下其原理。
type atomicLimiter struct {
state unsafe.Pointer
padding [56]byte // cache line size - state pointer size = 64 -8 ; created to avoid false sharing
perRequest time.Duration
maxSlack time.Duration
clock Clock
}
CPU CACHE 简介
通常情况下,我们无法直接干预对缓存的操作,但可以根据缓存的特点对程序代码实施特定优化,从而更好的利用高速缓存。高速缓存策略会尽可能地将访问频繁的数据放入cache中,该过程是动态的,cache中的数据不会一直不变,目前一般机器的CPU cache 可分为一级、二级、三级缓存,较旧的机器可能只有二级缓存。该缓存和RAM在空间和效率上的关系如下:
CPU
|
| Fastest Small
| ----------------------- Level 1 Cache (L1)
| |
| Faster Small
| ----------------------- Level 2 Cache (L2)
| |
| Fast Small
| ----------------------- Level 3 Cache (L3)
| |
| Slowest Large
| ----------------------- Main Memory (RAM)
cache 简单示意图:
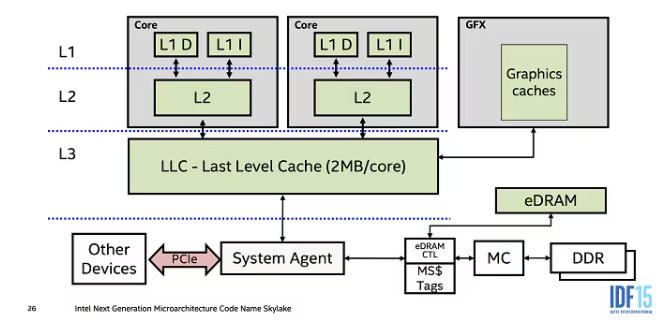
在lunix上可以使用lscpu来查看 cpu cache 的信息:
admin@al-hk-test-risk-app001:~$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz
Stepping: 4
CPU MHz: 2499.996
BogoMIPS: 4999.99
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K # 一级数据缓存
L1i cache: 32K # 一级指令缓存
L2 cache: 1024K
L3 cache: 33792K
NUMA node0 CPU(s): 0-7
说明该机器为8核且存在三级缓存,由于不同处理器之间都具有自己的高速缓存,所以当俩个cpu cache中都存有数据a,就有可能需要进行同步数据。而cache直接进行同步数据的最小单元为cache行大小,每一行cache的大小都是64bytes,当cpu 被告知 cache 第一行的第一个byte 为脏数据时,cpu会将每一行都进行同步。
场景测试
在cpu 高速缓存中存在以下规则,当一个CPU修改高速缓存行中的字节时,计算机中的其他CPU会被通知,其cache被视为无效。
场景设定
CPU1 读取数据a(a小于cache行大小),存入CPU1高速缓存;CPU2 读取数据a,并存入CPU2高速缓存;CPU1 修改数据a,a被放回CPU1高速缓存行,但该信息不会写入RAM;CPU2访问数据a时,发现其高速缓存已经失效,需要CPU1将数据a写回RAM中,然后CPU2重新读取该数据,可完成一次俩个CPU之间cache的同步。
测试代码
自己采用了golang进行测试上述问题,选择的方法主要采用了在runtime时,限制CPU核数的方式来指定是相同CPU,还是不同的CPU运行;读者也可以尝试使用golang中设置CPU亲和性的方式来指定CPU运行,其效果应该是一致的。
测试代码如下:
/*
* @Author: zengzh
* @Date: 2023-04-03 16:02:28
* @Last Modified by: zengzh
* @Last Modified time: 2023-04-03 16:50:49
*/
// https://www.duguying.net/article/set-cpu-affinity-binding-for-golang-program
package cpu_cache
import (
// "fmt"
"runtime"
"sync"
// "time"
)
const (
execCount = 100 * 1000 * 1000
)
type Bits struct {
a int
b int
}
type BitsWithCache struct {
a int
placeholder [64]byte
b int
}
func SetCPUCore(num int) {
runtime.GOMAXPROCS(num)
}
func thdFunc1(wg *sync.WaitGroup, bits *Bits) {
defer wg.Done()
// begin := time.Now()
for i := 0; i < execCount; i++ {
bits.a += 1
a := bits.a
_ = a
}
// end := time.Now()
// fmt.Printf("thd1 perf:[%d]us\n", end.Sub(begin)/time.Microsecond)
}
func thdFunc2(wg *sync.WaitGroup, bits *BitsWithCache) {
defer wg.Done()
// begin := time.Now()
for i := 0; i < execCount; i++ {
bits.a += 1
a := bits.a
_ = a
}
// end := time.Now()
// fmt.Printf("thd1 perf:[%d]us\n", end.Sub(begin)/time.Microsecond)
}
func thdFunc3(wg *sync.WaitGroup, bits *Bits) {
defer wg.Done()
// begin := time.Now()
for i := 0; i < execCount; i++ {
bits.b += 2
b := bits.b
_ = b
}
// end := time.Now()
// fmt.Printf("thd2 perf:[%d]us\n", end.Sub(begin)/time.Microsecond)
}
func thdFunc4(wg *sync.WaitGroup, bits *BitsWithCache) {
defer wg.Done()
// begin := time.Now()
for i := 0; i < execCount; i++ {
bits.b += 2
b := bits.b
_ = b
}
// end := time.Now()
// fmt.Printf("thd2 perf:[%d]us\n", end.Sub(begin)/time.Microsecond)
}
该代码为了方便测试和更直观展示,特意将测试部分细分为四个函数,同时为了避免其他因素等干扰,并没有采用泛型或者反射的写法,最少的减少其他因素的影响。在该测试代码中,与uber rate limit 中采用不一致的写法,uber 中的写法,是将结构体补充为 64byte 刚好占满一个 cache line,我们这里为了更加直观的展示,是将a,b中间填充一行,使得 a b placeholder 分别位于不同的cache line,若没有 placeholder 填充中间一行的话,a b将位于同一cache line,便会出现上述 cpu cache line 失效的问题。
分别对以下情况进行测试:
- 跑在俩个CPU上(该处没有严格指定CPU),没有填充placeholder
- 跑在俩个CPU上(该处没有严格指定CPU),填充placeholder
- 跑在一个CPU上,没有填充placeholder
- 跑在一个CPU上,填充placeholder
测试结果如下:
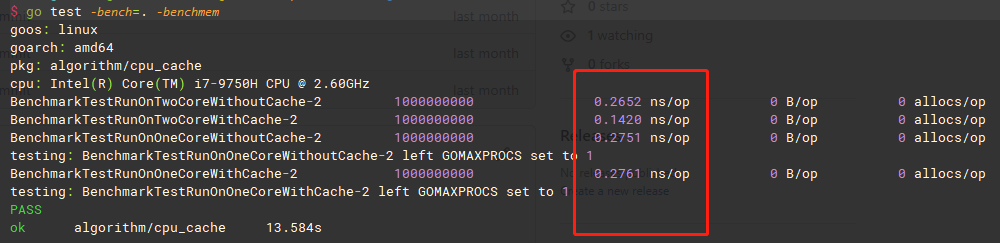
测试结论
综上,虽在测试时,并未严格指定运行的CPU,但是在其结果中可看出 情况1 2下,有无填充placeholder是存在明显区别的。而情况3 4下,无论有无填充placeholder,其结果都是一致的,这是因为情况3 4下,其实是在同一个CPU上运行,是不存在cache line失效的问题,但会比情况1慢一些,是因为只指定了一个CPU运行的。
总结
其实在日常工作中,某些对于CPU cache的优化还是比较重要的,但是在这个过程中如果为了追求性能将所有的共享字节都填入填充字节,可能会带来空间的浪费。在某些不同的硬件体系架构下,cache line的大小可能会不一样,或者可能会共享cache等等,所以在测试时要视具体情况而定的。
参考文章
https://www.makeuseof.com/tag/what-is-cpu-cache/
https://github.com/zengzzzzz/ratelimit/blob/main/limiter_atomic_int64.go
https://cloud.tencent.com/developer/article/1021491